The seven deceptions of microservices
Adapted from a talk I gave at Develop Denver 2019
Microservices have become ubiquitous in the architecture of modern tech companies - large and small. But are they better than previous development models? In this talk article, I will debunk the seven fictions that engineers tell themselves about microservices and why they might be an anti-pattern.
Disclaimer 1: I'm not an architect, nor do I pretend to be. These are simply observations I've made over the years as a software developer/manager. I've had the opportunity to watch two companies struggle under the weight that microservice architectures have imposed. Since relatively few people seriously question this new paradigm, I wanted to add my voice. Still, my experience is limited, and I'm open to feedback.
Disclaimer 2: There are other talks/articles on the Internet with similar titles. I neglected to check around before I came up with the title, and I'm too attached to let it go now.
What is the difference between a monolith and a microservice?
Before getting into the deceptions, let's define terms. Backend software architectures can be categorized into monoliths and microservices. Monolithic architectures are one or more servers that run a single application and are often deployed from a single repository. In the case of multiple servers, each server will run the same code. For most of the 90s and into the 2000s, this was the default architecture.
As the Internet grew up, larger companies began struggling under the weight of their monoliths. To address this issue, companies started to separate their code into components that ran on different servers. For example, a company might have a service to run logging, a service to make external API calls, and a service to do database management. Amazon's AWS was crucial to this development as it made it significantly easier to launch servers and manage infrastructure.
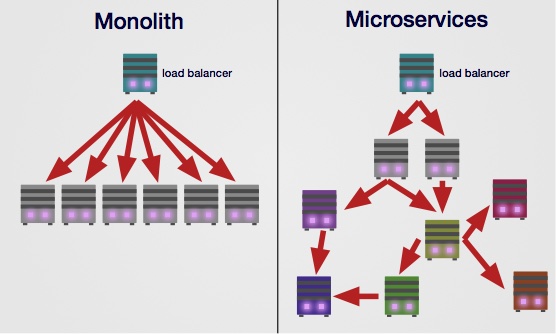
Over time, rather than being something that only large companies did, mid-sized and small companies started to embrace this new development paradigm. Soon, an industry grew up around microservices, and it has increasingly become the default for businesses looking to scale. Unfortunately, many companies are now experiencing various unintended consequences from their choices.
😈 Deception 1. Separation of concerns across services reduces complexity
"[Separation of concerns]" is the idea that walls should exist between unrelated code. When unrelated code needs to work together, it should be done with well-abstracted interfaces and minimal sharing of state. Introductory programming courses teach this as a standard software development axiom. The less your code knows about other code, the better. Similarly, the more one function does, the more you need to consider a complicated interrelationship of moving parts (e.g., complexity). And if there's one thing we strive for as competent engineers, it's reducing complexity.
I strongly believe in this axiom. Logically, does it follow that the best way to enforce a separation of concerns is to have your unrelated code running in different services with an API between them?
No. Absolutely not.
Classic single-process separation of concerns works because it minifies and simplifies the interface between unrelated code. In well-designed programs, this interface can be as little as a single function call with a return statement. Boundaries between unrelated code are inherently complex, and simple interfaces help to manage this complexity.
By contrast, in microservices, a function call is replaced with a network request. This new inter-service barrier is strictly more complex and unreliable. First, every network call requires a certain amount of boilerplate. Second, the engineer now needs to plan for any service to fail at any moment. In monoliths, by contrast, when code fails, the entire service fails. While this sounds bad, it's far more manageable because there is now only one failure scenario.
Worse in practice
The diagram below on the left illustrates Uber's microservice architecture from a few years ago. It is simple and can be understood within a few minutes. On the right is Uber's actual service map.

I think I'm on safe ground when I say, I don't think anyone at Uber knew how this worked. Those who have worked at sizable companies with microservice architectures know Uber's experience is not far off the mark.
There are two reasons for the disparity between model and reality. First, these diagrams are often grossly oversimplified. Architects design diagrams to communicate - not as a perfect representation of reality. But by hiding complexity, they also tend to bias decision-making. Would the technical leadership at Uber have gone the path they did if they knew what their architecture would become?
Second, once you've committed to microservices, every subsequent technical decision will reflect this architecture. The default for new and unanticipated functionality is therefore always to launch a new service. Over a relatively short amount of time, the graph becomes more and more complicated until we have the nest we see above.
😈 Deception 2. Microservices increase development speed
What happens when you take the "separation of concerns" axiom and apply it to people? You get siloed teams that are mostly independent. On the surface, this seems beneficial. If a team only needs to worry about their own service, then that has reduced their cognitive load and has made them more productive. Engineers now do not need to worry about complexity in other parts of the infrastructure.
The problem is that most new features require patches across multiple services.
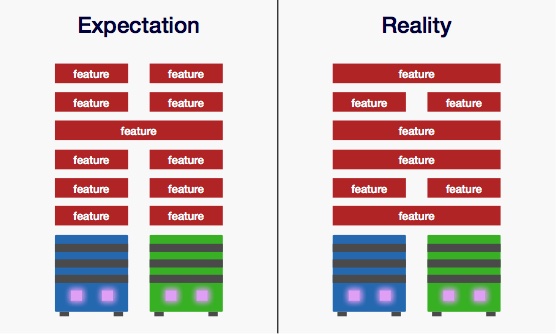 Many features require developing on two or more services
Many features require developing on two or more services
Developing multi-service features requires scheduling numerous meetings between teams with different priorities and capacities. These teams will likely need to work asynchronously, given their multiple different projects. You will also now need delivery managers to assign work and manage sprints.
From a technical standpoint, implementing a multi-service feature will likely require editing different repos. At the very least, it will require a way to test code running on multiple services.
For many companies, this multi-service test story is an afterthought. Architects designed the stack with the assumption that most development would happen on individual services. Multi-service features would be rare. How do you manually test a multi-service feature? You need to spin-up multiple containers on your computer and carefully set up the state for each of them. What about unit tests? Where would you put a unit test for a multi-service feature? Is it in repo A or B? Is that well documented? Often, deploys can break services that were not modified. It is easy to imagine a small bug in a data stream corrupting multiple downstream services. Is it reasonable to expect an engineer to understand every downstream service that might rely on their code?
If your organization has not invested significant engineering resources into building a multi-service testing process, expect a snail's pace of development for all but the most trivial features. Without a quality testing framework, seemingly simple tasks like "add pagination" can become multi-month multi-team efforts.
😈 Deception 3. It's safer to deploy small services than an entire app
The "rollback" is a reality of modern software engineering. I have certainly had my fair-share of rollbacks. As an engineer, when you deploy code that breaks something, you must rollback that deploy and revert the commit. No one wants rollbacks - especially not the engineer who deployed the code. Good companies, however, understand that bad deploys happen and must be managed.
One argument for microservice architectures is that deploying individual services is safer than deploying an entire application. When one service breaks, the other services will have fallbacks. The application as a whole will keep running, and customers will not notice.
There are multiple problems with this approach.
First, this assumes that your services can tolerate the random disappearance of any other service. This is Netflix's "chaos monkey" approach. However, building this into services is non-trivial, testing this requires resources, and unless this is a top engineering priority, actual adherence will vary.
Second, when deploying a multi-service feature, services will come online at slightly different times. For a few moments, your services will be different versions. There are multiple ways to handle this. Do you deploy in the middle of the night? Do you maintain different API versions in parallel? Do you use managed streams? All solutions require extra engineering resources. What happens when a deploy unexpectedly corrupts the state in a service that wasn't even part of the deploy? Do you have contingencies for everything that could go wrong?
While bad deploys happen with monoliths, there are multiple approaches to mitigate this (blue/green, canary, ...). While these approaches are also available for microservices, setting up and managing safe deployments is non-trivial and is easier to do with one service than many services.
😈 Deception 4. It is often advantageous to scale services independently
In every application, there are parts that run frequently and parts that run rarely. Parts that run rarely need fewer resources than parts that run frequently. Does it then make sense to scale these parts separately?
On a basic level, the reason for scaling is because your software needs more of some core resource. This resource might be CPU cycles, memory, disk space, or network. For example, when a CPU is running at 100%, it is possible to launch another service to take the pressure off.
For most applications, horizontal-scaling (cloning the monolith) is sufficient. Horizontal scaling is low complexity, and numerous cloud services can do this with minimal configuration.
There are two common reasons why you might want to scale individual microservices instead. First, if your code has substantial parallel sections, assigning blocks of computation to different "workers" can be beneficial in some cases. Importantly, the data-transfer and spin-up overhead must be low relative to the total computation per task. So it doesn't make sense to send ten calculations that take 10ms each to servers with 100ms of overhead. Sequentially, 10x10ms = 100ms. In parallel 10ms+100ms = 110ms. If, however, each calculation took 100ms, it would make a lot more sense to parallelize them.
Second, it might make sense to scale individual microservices if resource needs vary throughout the request. For example, if a request is memory-bound at the beginning and CPU-bound at the end, it might make sense to put the beginning of the request in a high-memory service and the end in a high-CPU service. Even then, unless you are running at unicorn-scale, the financial advantages of independently scaled services will not likely offset the additional complexity.
Plus, your attempts to save money might tragically backfire...
 Happy cloud customers
Happy cloud customers
😈 Deception 5. Microservice architectures are more performant
There are a few rules-of-thumb that I learned in engineering school.
- Reading RAM will take 10x as long as reading the L2 cache
- Reading the hard drive will take 10x as long as reading RAM.
- Reading from the network will take 10x as long as reading from the hard drive.
These numbers were rough approximations. With time, they have certainly become less accurate. However, let's look at the actual scale between network communication in a data center and reading from RAM: In 2009, reading 1 MB sequentially from memory can be estimated to be 250,000 ns In 2019, in AWS data-centers, communication between two EC2 instances can be as fast as 5 GBPS
Doing the math:
- RAM in 2009: 1 megabyte in .25 ms
- 1 megabyte within a datacenter in 2019: 5 gigabits in 1 second = .625 gigabytes in 1 second = 1 megabyte in 0.64 seconds
Not much slower right? Until we realize that:
- Those network speeds are best-case
- We are comparing 2009 to 2019
- To send that megabyte over the super-fast AWS network, we still need to read it from RAM. So the real lower limit is 0.64 + 0.25 = 0.89 seconds
Assuming you have only one dependency, you now have created a bottleneck that is, at minimum, x3.5 slower than it would have been if you just kept the code running on the same machine. In reality, several additional factors will slow network communication to more extreme ratios.
No wonder we now use byte-streams to shave a few milliseconds off of each request. Of course, with byte-streams, it is no longer possible to debug inter-service communication without tooling.
😈 Deception 6. Managing multiple services won't be hard
There is a particularly common lie that software engineers like to tell themselves. Perhaps you've heard it before. It is some version of "this won't take long," "give me a few hours," or "I could do this in a weekend." Good project managers will understand this and multiply their engineer's estimates by four (or forty... depending).
That same optimism is present in a decision to use microservices. It is not as simple as getting everyone an AWS certificate and moving some code around. There is actually a tremendous amount of unexpected overhead. Here are some categories of people and things that you will now need:
- Architects. You will need a few people to draw nice-looking over-simplified diagrams and give presentations.
- Release management. You will now need to coordinate your deploys and manage multiple pipelines. This coordination will require common tooling and a team to maintain that tooling.
- DevOps. "Regular" engineers will have neither the expertise nor the will to configure their services properly. They will also likely be terrible at securing them.
- Data engineers. If you are lucky enough to have also broken up your data storage per recommendations, you will now need a team to extract this data to one place for analytics.
- Config files. While a few extra YAML files don't sound so bad, your most dangerous bugs will now live here. They will also be incredibly difficult to test and debug.
Not only will you need to pay all of these additional people, but you've also exponentially increased the number of communication channels in your engineering organization. This will slow everyone down.
😈 Deception 7. Microservices will work if you design them carefully from the ground up
For this, I'll leave you with a quote.
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system. - Gall's law
So what then?
Why are microservices so popular when there are such apparent downsides?
I believe that most engineers (myself included) have some level of imposter syndrome. Too often, we are thrown into situations where we are not fully competent but still need to be productive. During such times, it's safer to lean on the work of others and "best practices." However, we are quick to assume that these "best practices" are well-thought-out or apply to our problems. Cloud vendors gain when you provision more services. Microservice advocates gain when you buy their books. They both have incentives to sell you more complicated technology than you need.
Regardless, there are situations where I believe microservices might be the correct choice. If you are Google or Facebook and handle billions of active users across dozens of products, maintaining a monolith isn't an option. If you have substantial parallelizable tasks, monoliths alone won't work.
My goal is more to convey that the design of your backend services is incredibly consequential, and no design choice is a silver bullet. It doesn't matter whether we are talking about microservices vs. monoliths, SQL vs. NoSQL, or Python vs. Node. It is unlikely that any technology will be strictly superior for all use cases.
Accordingly, it makes sense to be very deliberate about your thinking, question all of your assumptions, and make architectural decisions soberly. Your choices might just make or break your company.